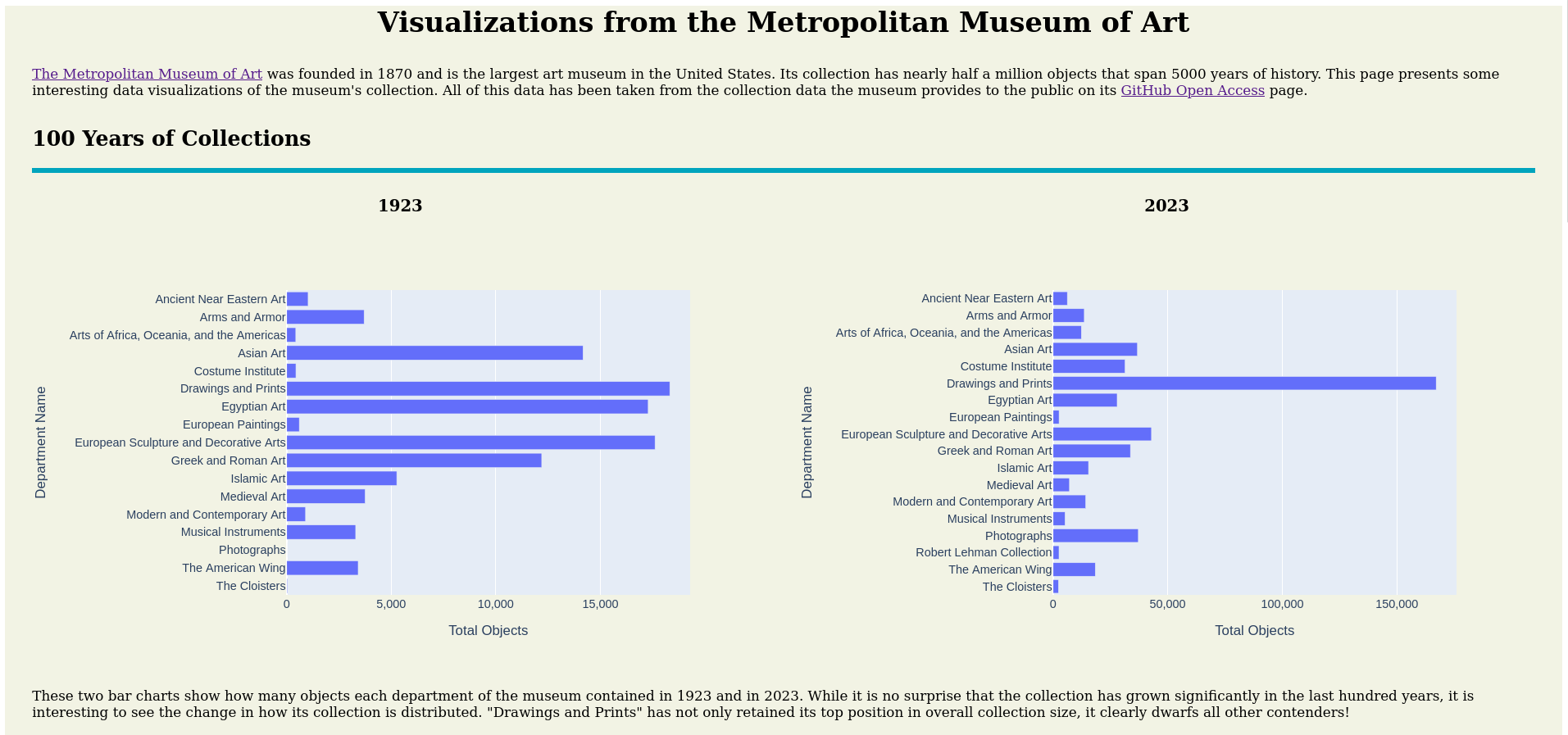
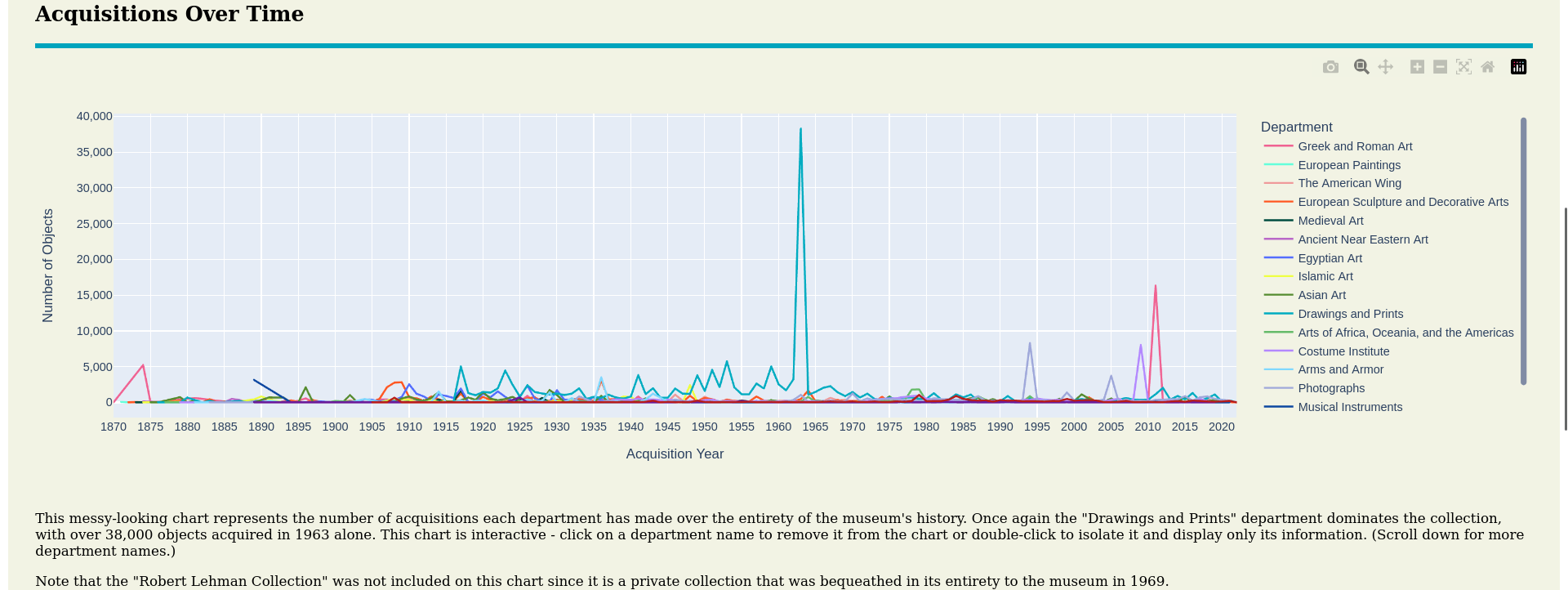
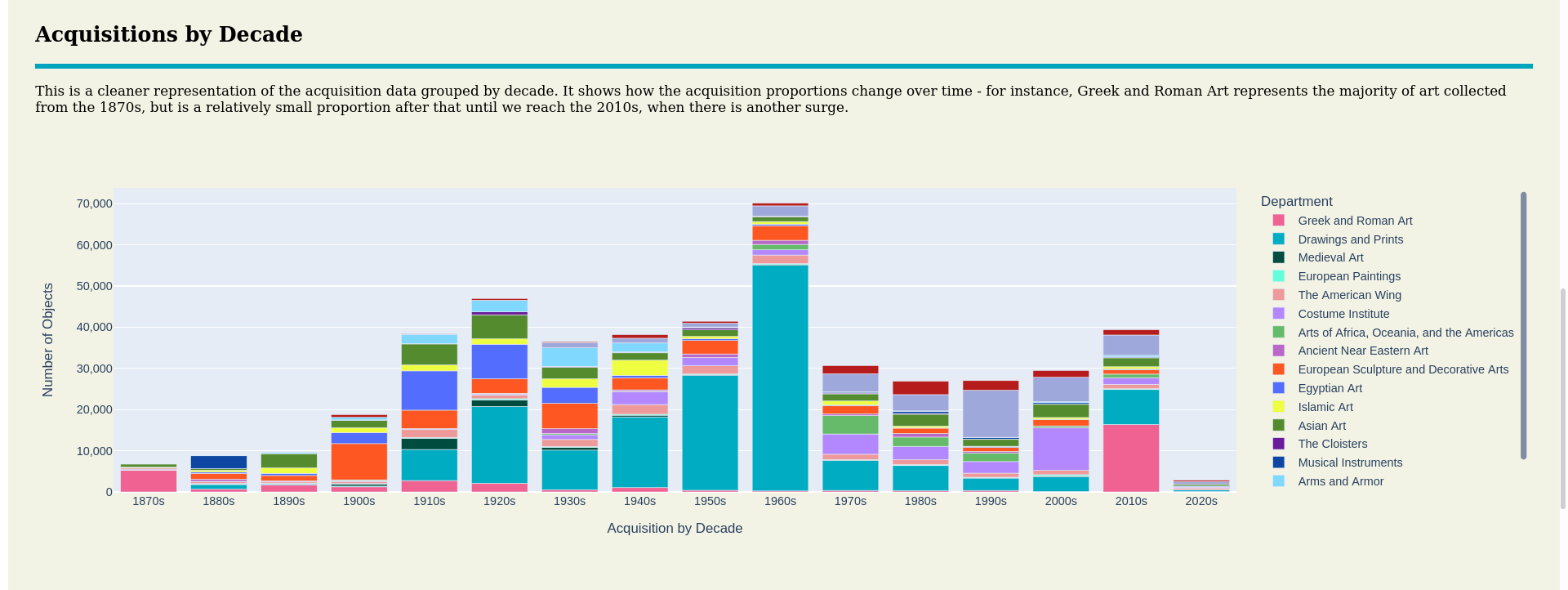
The Metropolitan Museum of Art Data Visualization Project
This is a Data Visualization project using collection data from the Metropolitan Museum of Art. It uses Python, Pandas, Numpy, Plotly, and Dash.

Software portfolio for Erica Neely